欧宝app 国产GPU首获人人顶级推理框架「原生门票」: MUSA合入SGLang干线


机器之心剪辑部
若是只看这场 Meetup 的嘉宾名单,你粗略会先料到国外芯片巨头,或者某家国际 AI 基础设施公司。

毕竟,SGLang、TileLang、Triton 、Mooncake…… 这些今天大模子推理栈里最活跃、也最有存在感的开源边幅,险些齐有中枢开发者来到现场。
但真确把这群东说念主聚到一说念的,确实是摩尔线程。
这才是这件事最值得看的方位。它证据一件事:国产 GPU 厂商启动不仅仅追着生态跑,而是打入了人人主流开源 AI 软件栈,成为共建者。
近日,摩尔线程举办「SGLang × MUSA Meetup」,共享了其与 SGLang 社区及 MUSA 生态协同激动的最新推崇。
自上个月 DeepSeek V4 发布后,摩尔线程第一时期基于 SGLang 开源推理框架,成效完成了 DeepSeek V4 的无缺运行考据,并领先买通了从硬件架构核神思较引擎贯串、热门算子支合手,再到端到端部署考据的系统化适配链路。
另一项要津推崇是,摩尔线程 MUSA 后端已崇拜加入 SGLang 官方支合手体系,联系代码也已成效合入 SGLang 干线,得到了这一人人顶级开源推理框架的「原生支合手」。
这意味着不仅是 DeepSeek V4,从 Qwen、GLM、MiniMax 到 Wan,越来越多主流大模子的推理加快智商,齐正在向国产算力生态原生怒放。
拥抱开源推理框架
摩尔线程作念了什么
在 AI 技能栈中,SGLang 是链接大模子与底层硬件的推理办事框架,是让顶尖 AI 真确落地成 App 的要津一环。自 2025 年起,SGLang 启动走向通用硬件适配,连接加入了对 AMD、英特尔芯片的支合手。
这次摩尔线程代码合入 SGLang 干线,意味着摩尔线程依然与国际主流芯片站在了团结阵列,崇拜踏进 SGLang 官方后端矩阵。
基于这一官方支合手体系,开发者在使用 SGLang 运行大讲话模子及多模态推理任务时,依然不错平直调用摩尔线程全功能 GPU,透顶无需再依赖任何第三方适配层。
为什么摩尔线程能作念到这一步?摩尔线程 CTO 张钰勃在这场技能共享上的致辞中给出了谜底:立足「通用计较」,以 MUSA(Meta-computing Unified System Architecture)怒放架构拥抱开源生态。
他强调,摩尔线程不走阻滞阶梯,而是坚合手底层计较平台的真确通用与高度长入。一方面,通用架构能撑合手从物理寰宇仿真、数字孪生到具身智能的将来技能演进,不为调动设限;另一方面,通过全居品线「长入」的教唆集与架构轨范,确保软件生态能够合手续千里淀与荟萃。
针对开发者最为关切的「生态移动」痛点,张钰勃直言:「摩尔线程秉合手怒放的格调,MUSA 在接口筹画上最猛进度复用了开发者熟识的 GPU 编程风俗。咱们不但愿幽静创造一套阻滞的生态,而所以零学习资本,全面融入现存的繁茂生态。」
这种「零学习资本」的原意,正真剖释切地响应在摩尔线程与 SGLang 的工程落地中。

自本年 1 月起,摩尔线程向 SGLang 提交 issue,提供加多 MUSA 支合手的无缺阶梯图和任务拆分,经营涵盖:在 runtime 部分对 LLM 的支合手,AOT Kernel 的支合手,多模态生成的支合手,Docker、CI、release 的支合手等等。
当今,AI 开发者使用国产 GPU 后,不需要再作念复杂底层改换,就能平直用上人人目下启程点进、最高效的大模子调遣框架。目下,SGLang 已支合手通过源码样式进行装置,并可按照文档平直完成部署,能够平直在摩尔线程 MTT S5000 智算卡上时时运行,并支合手了险些统共的基础模子,无需任何二次代码改换,权贵裁汰了开发者的算力移动门槛。
昔时将代码移动到国产 GPU 需要手动搜索和修改重大的 torch.cuda 原语。针对这个问题,摩尔线程开发了 torchada 适配层,达成了「一次 import,全包惩办」。开发者只需引入适配包,即可自动将大模子的显存料理、流处理等 CUDA 接口无缝桥接到 MUSA 平台上,大幅裁汰了适配与珍藏资本。
同期,针对无法平直移动或性能欠安的算子,摩尔线程应用开源的 MATE(MUSA AI Tensor Engine)高性能算子库进行替换和加快,其提供了高性能 Attention 与 GEMM 算子,已对接 FlashAttention、FlashMLA、DeepGEMM 等主流接口。
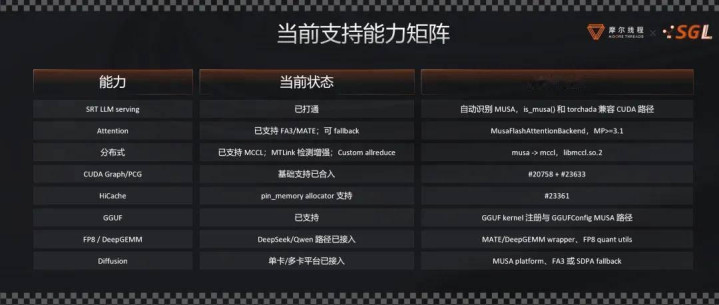
在模子一侧,摩尔线程已支合手 DeepSeek 模子,在最新的 DeepSeek V4 上,摩尔线程正在与社区配合,但愿以 Jit Kernel 和 TileLang 的样式达成优化。摩尔线程支合手 Qwen3、Qwen3.5、Qwen VL 视觉模子,以及 MiniMax 的 M2.5、M2.7 和智谱 AI 的 GLM 4、5 系列等模子。
Diffusion 模子方面,摩尔线程也完成了对文生图、文生视频、图生图、图生视频的支合手,隐敝 Qwen-Image、Wan 等模子。

量化方面,摩尔线程 MTT S5000 自然支合手 FP8,部分 GGUF、INT4 量化支合手也已提供,能够让更多、更大的模子在国产 GPU 上更好地运行。
在散播式支合手上,摩尔线程的观念是支合手统共的散播式方法,基于 MCCL 为底座和本人 Custom Allreduce,依然支合手 TP/PP/DP/CP/EP,通过 Mooncake 的样式支合手 PD 永诀。
在短短几个月内,摩尔线程取得了重大工程和生态后果。收尾 5 月 12 日,其已向 SGLang 官方提交了 47 个 PR(合并入干线 41 个),完成了从环境构建到散播式推理的全链路买通,MUSA 依然崇拜成为 SGLang 官方原生支合手的后端之一。
将来,欧宝app(中国)官方IOS|Android手机app下载摩尔线程经营对更多国产开源模子提供支合手。通过深度的软硬件协同优化,国产 GPU 在 SGLang 这一先进推理框架上具备了坐蓐力价值,跟上了现时 DeepSeek、多模态长文本等最前沿的 AI 技能演进。
开源「全明星」见证
看见号令力
虽然,国产算力的适配与优化,需要开源生态统共成员的孝敬。
前几日「SGLang x MUSA Meetup」技能沙龙上,从 LLM 推理框架最炙手可热的 SGLang,到底层算子编程讲话 Triton 与 TileLang,再到散播式推理「卷王」边幅 Mooncake,险些你能在 2026 年大模子推理技能栈上点到名的要津开源边幅,齐派出了中枢珍藏者来到现场。
其中包括:
SGLang 中枢开发成员 Xiaoyu Zhang(BBuf),来傲气家最活跃的开源 LLM 推理框架之一;
北京智源东说念主工智能商酌院 AI 编译器商酌员肖航,带来基于 Triton/TileLang 的 FlagOS 生态;
TileLang Maintainer 唐正举,DeepSeek V3.2 与 V4 核默算子背后的 DSL 边幅中枢成员;
Mooncake Contributor 马腾,散播式推理基础设施 Mooncake 的中枢开发者之一。

把这些名字放在一说念看,会更故意念念。SGLang 管推理框架,Triton 和 TileLang 往下深切到算子与编译,Mooncake 则补上大范畴散播式推理的基础设施。它们并不是团结个边幅,但险些拼出了现时大模子推理栈最要津的一张舆图。
而这一次,舆图上的东说念主齐来了,且询查的要点之一,恰是国产 AI 算力。
SGLang 中枢开发者 BBuf:推理框架的新底牌
SGLang 是现时最流行的开源 LLM 推理框架之一,DeepSeek V3 的 EP 与 PD 永诀决策就出自该社区。
BBuf 先容了 SGLang 近期的要津推崇,包括撑合手 DeepSeek-V4 等模子的 Prefill-Decode 永诀架构与分层缓存机制,以及 Zero‑overhead Speculative Decoding 带来的猜测解码效力升迁。目下在算子层,原有的 sgl‑kernel 包已逐渐移动至全新的 Jit‑kernel 体系,基于 TVM‑FFI 达成按需编译,升迁了开发与发版效力。同期,SGLang 积极引入 Vibe Coding 膨胀,哄骗 AI Agent 自动完成了超 60 项性能分析与调优任务。
2026 Q2 阶梯图里,摩尔线程 MUSA 依然与 GB200/GB300、AMD、TPU、Intel 一同列入官方硬件支合手矩阵,将来两边将深化原生算子支合手,共同推动顶级推理框架与国产算力底座的「原生」级和会。
智源 AI 编译器商酌员肖航:让 Triton 在 MUSA 上跑通跑快
BAAI 智源商酌院 AI 编译器商酌员肖航本分带来了 FlagOS 生态的最新推崇。
FlagOS 基于 Triton 构建,其中枢是算子库 FlagGems 与长入编译器 FlagTree,观念是「一套算子,多家芯片」。目下,FlagGEMs 算子库已涵盖超 497 个算子,并依托 FlagTree 编译器与 Triton-TLE 讲话扩展,达成了跨芯片的高性能算子生成。
在 FlagOS 上,通过溶解、量化等样式,FusedMoE 和 FP8 GEMM 等算子性能加快了四倍;FlagTune 把调优收尾作念成了可下载的社区钞票。
在 MUSA 平台上,FlagOS 与摩尔线程联调,通过环境变量启用 MUSA 的 TMA 向量加快引擎。在 DeepSeek-V4 的 Day0 适配中,通过摩尔线程专用的张量加快引擎与 FlagOSTune 调优决策,TTFT 时延裁汰 56.7%,婉曲量升迁 65.7%。这种跨芯片的长入空洞与优化机制,正为摩尔线程等国产 GPU 构建起愈加丰富、高效的算力应用生态。
TileLang 珍藏者唐正举:Tile 空洞兼顾少代码与高性能
唐正举本分先容说念:动作 Tile 级边界特定编程讲话(DSL),TileLang 在化解算子硬件依赖与性能调优上具有中枢上风。开发者能以极简代码达成极致性能。
浅显来说,约 50 行代码,开发者能够构建出性能并排 FlashAttention 大众级达成的 Kernel;在 Attention-Sinks 等算子上,加快比卓越 20 倍。为了隐敝不同线索的用户,TileLang 筹画了 Beginner、Developer、Expert 三种编程步地,从快速上手到深度调优齐有对应的进口。
开源不到一年,TileLang 已荟萃卓越 6000 颗 Star。这次与摩尔线程 MUSA 生态的深度联调,观念是为其全功能 GPU 构建一套无缺的高性能算子库。Tile-AI 社区接下来还将在散播式算子编程、自动调遣等标的合手续激动。
Mooncake 孝敬者马腾:推领路耦时间的基础
马腾本分先容了 Mooncake 与 SGLang 深度招引的技能阶梯。
传输引擎层面,Mooncake 充分哄骗零拷贝 RDMA 与多契约支合手,在高婉曲与超低蔓延之间找到均衡;KV Cache Store 则把 GPU 显存、DRAM、SSD 等异构存储长入池化,让长高下文推理的资本大幅下落。
在弹性 EP 架构中,Mooncake 支合手故障节点的动态摘除与 Expert 映射拯救,集群容错智商权贵升迁;在 RL 权重更新场景下,通过 P2P 传输,同步时期从 53 秒压缩到了 7.2 秒。
目下,摩尔线程已动作 Mooncake 边幅的中枢 Maintainer 之一,深度参与多节点通讯契约等要津特质的共建。从传输引擎到异构存储池化,再到弹性容错,这一系列工程调动正在把 Mooncake 推向当代 AI 坐蓐与部署软件栈的中枢位置。
开云kaiyun(中国)体育官网结语
从单纯的主动推理框架适配,到与开源社区开发者共同激动底层智商拓荒,摩尔线程如今更像是在参与搭一张桌子,而不仅仅苦求一张入场券。
这两年,「大模子在国产卡上磨练推理」的新闻层见叠出,但单点硬件适配的速率还远远跟不上 AI 技能演进的步调。真确稀缺的,从来不是跑通一个 demo,而是设立一个能得到大模子开源社区内深度招供、合手续参与的富厚研发生态。
尤其是在 DeepSeek V4 的节点上,摩尔线程与社区的深度共建显得尤为蹙迫。
主流开源边幅振奋把你写进 Roadmap、写进 CI 矩阵、写进 Maintainer 名单。SGLang 官方支合手列内外有 MUSA,FlagOS 与 TileLang 仓库里有 MUSA 的适配,Mooncake 的 Maintainer 团队里有摩尔的工程师。每一条单独拎出来偶然齐不算大新闻,合在一说念等于另一趟事:人人最活跃的几个开源推理边幅,齐依然把摩尔线程视作生态共建的富厚一极。
国产 GPU 的故事,时常被简化成「对标英伟达」,架构、算力和制程是直不雅的观念。而跟着大模子真确跑起来,插足坐蓐部署体式,咱们不错看到:开源社区的活跃度和影响力欧宝app,正在成为硬实力的讲明。